There must be a time in every Rails developer’s life where they had to search the above question.
The dreaded Rails Asset Pipeline is perhaps one of the most confusing features in Rails, especially if one deviates from its traditional usage. In this post, I describe one of the reasons why your assets might not be loading in production, despite working fine in all your pre-production environments.
The Error
I had faced this issue in on one of my recent production deployments. As soon as I deployed my Canary pod in production, I began receiving the following error for some requests to fetch the CSS and JS files.
500 : Internal Server Error
No route matches [GET] /assets.
Seeing the error rate increase I immediately rollbacked, which stopped the errors. When I began tracing the logs, I was shocked to find that the errors were not just happening in the Canary pods, but all other production pods also. I was shocked because I had not delpoyed the other production pods with the new code yet.
How my deployments were configured
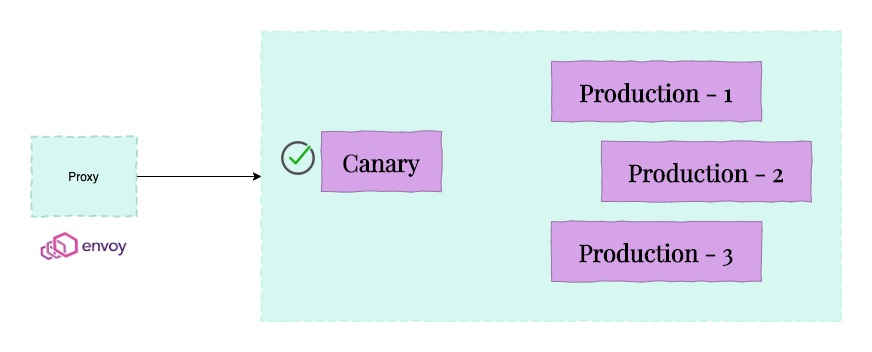
MMMy service was fronted by an Envoy Proxy which redirected user requests to one of four pods. We used rolling deployments to deploy new code into production. A Canary is first deployed followed by the other production pods.
The Cause
After careful analysis of the error logs, I found out that this issue was not a Rails issue but an issue of how our deployments were configured.
Let’s say before my recent deployment, I had two asset files common.css and common.js. Since the default behaviour of Rails Asset Pipeline is to minify and fingerprint the asset files (as it should), the filenames are modified to the following :
common-489839434903.css
common-819894348394.js
Fingerprinting Asset Files
The fingerprint suffix in the filename is a hash of the contents of the file. It changes whenever the contents of the file is updated. This behaviour optimizes the load time of the web page, as the browser does not request the asset file, if the file with this name is already cached in the browser.
Assets and HTML fetched from different servers
When a user sent a request to the backend to load a page, the HTML was served by one of the following servers : –
- Either the - Newly deployed canary
- Or - Any one of the remaining production servers
Our problem arose because - it is not necessary that the server which serves the HTML will also serve the asset files requested by the HTML.
So if the initial request to load the HTML page went to the canary pod, it will respond with an HTML containing new asset files. Consequently, the request to fetch these asset files could have reached a pod with an older deployment. If so, the pod would not be able to find the new asset files. Rails being unable to find the required asset file will then forward the request to the controller which will eventually lead to No route matches [GET] /assets error.
The vice-versa is also true, i.e. initial HTML being loaded by the pods having the older deployment, and the request to fetch the assets mentioned in the HTML going to the newly deployed Canary pod.
This was the reason why, on just deploying the Canary pod, I started receving errors in all pods.
The Fix
As an immediate fix, I removed asset fingerprinting.
In my use case, I was only dealing with two asset files. Moreover, my asset files were going to be rapidly changing. Thus, I did not see the benifits of fingerprinting in the short term future.
For the long term, I may plan on introducing an NGINX layer which will be responsible for caching and serving all my assets.